
JINIers
jupyterlab 이용 빅쿼리 호출하기(Bigquery → Vertex AI) 본문
jupyterlab 이용 빅쿼리 호출하기(Bigquery → Vertex AI)
vertex ai > workbench > user-management notebooks > new notebook 으로 노트북 생성 > open jupyterlab

notebook > python3으로 들어가 > ___.ipynb 파일을 만든다.

[1]
!pip install google-cloud-bigquery
!pip install --upgrade google-cloud-bigquery-storage
[2]
from google.cloud import bigquery
client = bigquery.Client()
[3] 전체 데이터 추출
sql = """
SELECT
sensorID, status, temperature,
COUNT(1) AS count
FROM
`pubsubtt.senset.sentable`
GROUP BY
sensorID, temperature, status
ORDER BY
count DESC
"""
df = client.query(sql).to_dataframe()
df.head()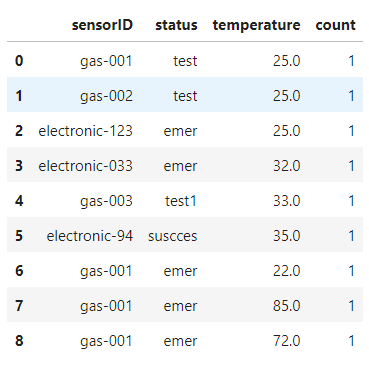
* 불러오는 bigquery의 경우 pub/sub으로 받은 json 데이터를 이용하였다.
물론 저 값은 전부 내 임의로 지정함
[4] gas 데이터만 추출
sql = """
SELECT
sensorID, status, temperature,
FROM
`pubsubtt.senset.sentable`
WHERE
sensorID LIKE 'gas-%'
GROUP BY
sensorID, temperature, status
"""
df = client.query(sql).to_dataframe()
df.head()
# 쿼리 구문 에러 났을 때
▶ bigquery > 새로 탭 생성 > sql = """ """ 을 제외한 나머지 구문을 먼저 넣고 돌려본다. 데이터가 뽑히면 그대로 주피터랩에 넣고 'sql = """ """ ' 을 포함하여 돌린다.
와 이걸 3일동안 에러를 못찾고 있다가 부들부들
sql 쿼리문 검사기에 돌려도 정상이라고 떠서 에러를 못찾고 있다가 !!! 부들부들 ㅜㅜ
도움을 주셔서 해결할 수 있었음
[5] 추출데이터 요약 / 평균치가 나옴
df.groupby(['sensorID', 'status']).mean()
[6] 추출데이터 그래프로 만들기
df.plot()
근데 좀 그래프가 이상해
당연함 난 주피터랩을 처음써보니까 하나도 몰라
아마도 추출된 가스 데이터[4]를 이용해서 그래프가 만들어진 것 같음
x와 y축 지정을 하나도 안해줬고 그래서 서치한 대로 일단 만들어서 돌린거라 고양이 모양으로 나옴
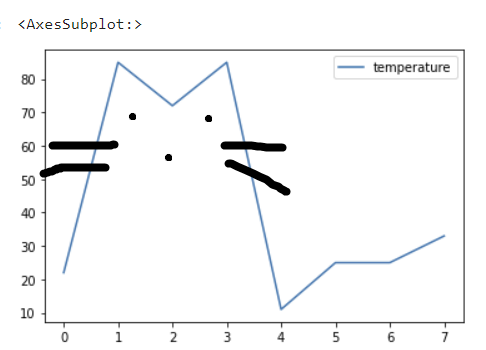
흥 귀여워
귀여우니까 너 메인임
[7] electronic 데이터만 추출
sql = """
SELECT
sensorID, status, temperature,
FROM
`pubsubtt.senset.sentable`
WHERE
sensorID LIKE 'electronic-%'
GROUP BY
sensorID, temperature, status
"""
df = client.query(sql).to_dataframe()
df.head()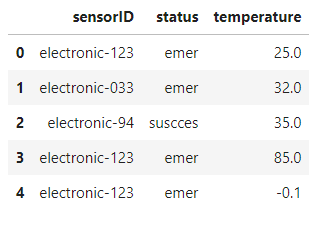
[8] 데이터 요약
df.groupby(['sensorID', 'status']).mean()

[-] 원래는 얘를 돌려야한다.
pivot_table = df.pivot(index='sensorID', columns='status', values='temperature')
pivot_table.plot(kind='line', stacked=True, figsize=(15,7));
▶ 코드는 맞지만 에러가 뜨는 이유 : 중복값이 존재하기때문에 표를 만들수가 없다.
→ 1차적으로 요약해 통계량을 낸 뒤[5], 피벗테이블로 전환
나같은 경우에는 data에 timestamp가 없어 line 형식으로 변환해주기 어려웠다.
→ bigquery에 timestamp를 넣어주도록하자.
끝.
※ 참고
* 빅쿼리 가이드 : https://zzsza.github.io/bigquery/guide.html
'GCP > 구성연습' 카테고리의 다른 글
| GitLab 저장소 → Cloud Source Repositories 로 미러링(CI방법) (0) | 2022.06.22 |
|---|---|
| Cloud Function (0) | 2022.06.16 |
| json data → pub/sub 전송 (0) | 2022.05.12 |
| [GCP] 기본 구성 aws → gcp 구성 변경_5-1(LB 404 not found 도메인 재연결) (0) | 2022.04.14 |
| web-server, WAS server 설치하기 (0) | 2022.04.07 |



