
JINIers
[PCK] Troubleshooting Workloads on GKE for Site Reliability Engineers 본문
[PCK] Troubleshooting Workloads on GKE for Site Reliability Engineers
JINIers 2022. 2. 7. 17:20Troubleshooting Workloads on GKE for Site Reliability Engineers lab
(사이트 안정성 엔지니어를 위한 GKE의 워크로드 문제해결)
연구 목표
1. Google Kubernetes Engine(GKE)의 리소스 페이지 탐색
2. GKE 대시보드를 활용하여 운영 데이터를 빠르게 확인
3. 특정 문제를 캡처하기 위한 로그 기반 측정항목 생성
4. SLO(서비스 수준 목표) 생성
5. SRE 직원에게 인시던트를 알리는 경보 정의
1. GKE 리소스 페이지 탐색
kubernetes engine > clusters > cloud-ops-sandbox 클릭 > node 탭 > 단일 노드 풀 확인 > 오른쪽 점세개 눌러 > view in Metrics Explorer > nodename 필터 확장하기
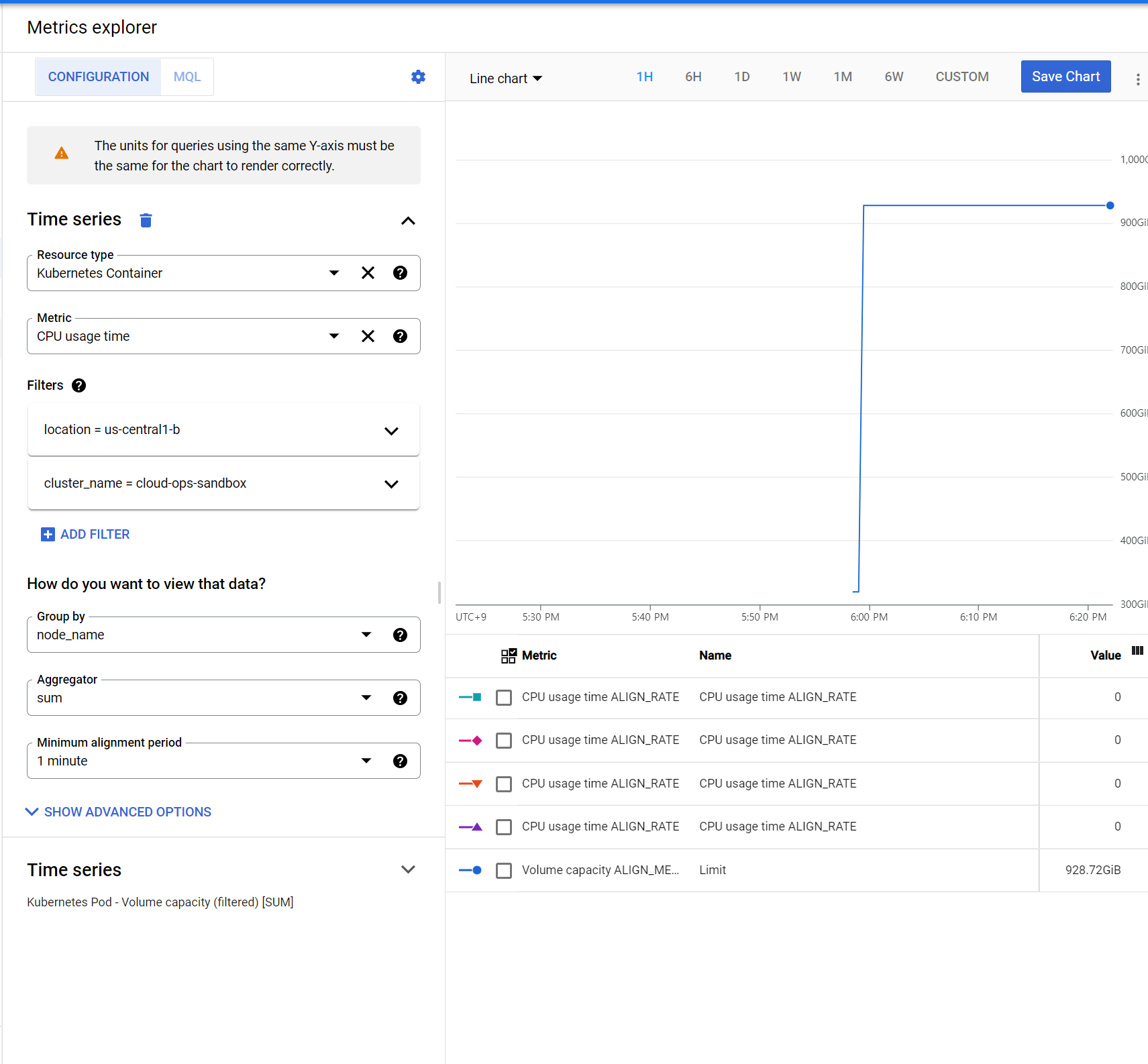
2. GKE 대시보드를 통해 운영 데이터 액세스
kubernetes engine > service & ingress > frontend-external ip 클릭 > 사이트 접속 에러
monitoring > dashboard > GKE > 모니터링 섹션 등장!
add filter > workloads > recommendationservice > apply


workloads 섹션 > recommendation service 클릭 > 심각도 설정

invalid literal for int() with base 10: '5.0' // 서비스코드에 버그있음
shell >
git clone --depth 1 --branch cloudskillsboost https://github.com/GoogleCloudPlatform/cloud-ops-sandbox.git
// 클론 만들기
cd cloud-ops-sandbox/sre-recipes // 디렉토리 이동
kubernetes engine > clusters > cloud-ops-sandbox 의 점 세개 > connect > run in cloud shell 누르면
gcloud container clusters get-credentials cloud-ops-sandbox --zone us-central1-b --project qwiklabs-gcp-02-0115aad4ba63 // 이게 뜸
그럼 엔터
./sandboxctl sre-recipes restore "recipe3" // apply 명령 실행
kubernetes engine > services&ingress > 다시 frontend-external ip 클릭 > 사이트 재접속 확인
3. 로그 기반 지표를 통한 사전 모니터링
업데이트된 recommendationservice코드가 예상대로 작동하는지 확인하고 향후 인시던트가 다시 발생하지 않도록 하려면 로그 기반 메트릭을 생성하여 로그를 모니터링하고 향후 유사한 인시던트가 발생할 때 SRE에 알리기로 결정합니다.
이 섹션에서는 이전 섹션에서 발견된 오류와 관련된 로그 기반 측정항목을 생성합니다.
로그 기반 메트릭을 사용하면 로그의 오류를 추적하는 메트릭을 정의하여 최종 사용자가 발견하기 전에 유사한 문제 및 증상에 사전에 대응할 수 있습니다.
operation logging > logs explorer > create metric 클릭 > 새탭이 쨔란 하고 열림 > create logs metric > 구글에서 시키는대로 > create metric

4. SLO(서비스 수준 목표) 생성
monitoring > services > recommendatin service 클릭 > create SLO > 설정 설정 > SLO create


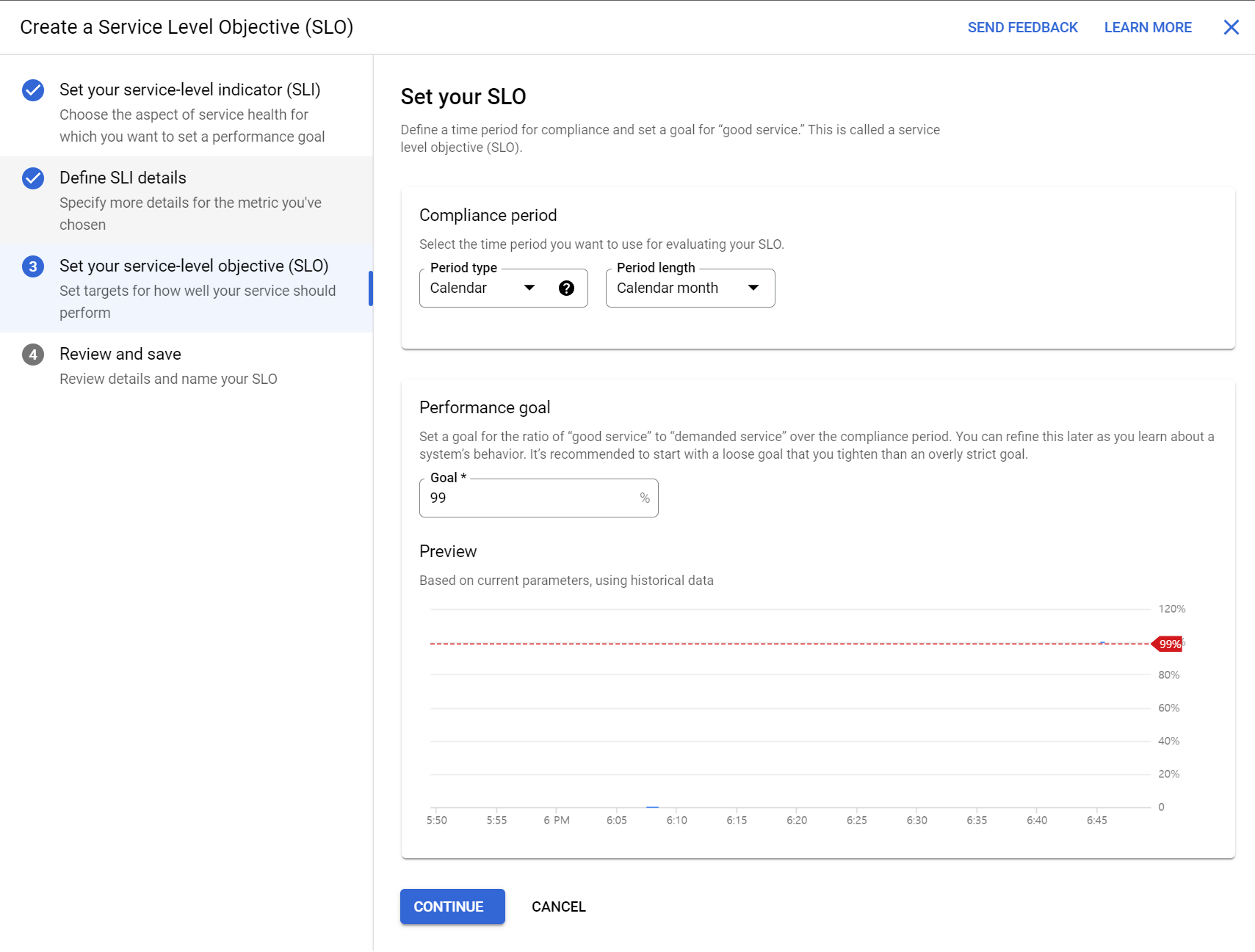
error budget 탭 클릭 > 그래프 확인

5. SLO에 대한 경고 정의
SRE 팀에 서비스 수준 목표 집합 위반을 사전에 알리려면 SLO를 위반할 때 트리거되는 경고를 정의하는 것이 가장 좋습니다. 경고는 이메일, SMS, PagerDuty, Slack, WebHook 또는 PubSub 주제 구독을 포함하여 선택한 알림 채널을 호출할 수 있습니다.
monitoring > services > recommendatin service 클릭 > create SLO alert 클릭 > 2단계 아무것도 누르지말고 next > save

'GCP > Qwiklabs' 카테고리의 다른 글
| [PCK] PCA Prep - Update and Scale Out a Containerized Application on a Kubernetes Cluster (0) | 2022.02.09 |
|---|---|
| [PCK] PCA Prep - Google Cloud Essential Skills : Challenge Lab (0) | 2022.02.09 |
| [PCK] Continuous Delivery Pipelines with Spinnaker and Kubernetes Engine lab (0) | 2022.02.07 |
| [PCK] Deploying Apps to Google Cloud lab (0) | 2022.02.04 |
| [PCK] Building a DevOps Pipeline lab (0) | 2022.02.03 |



